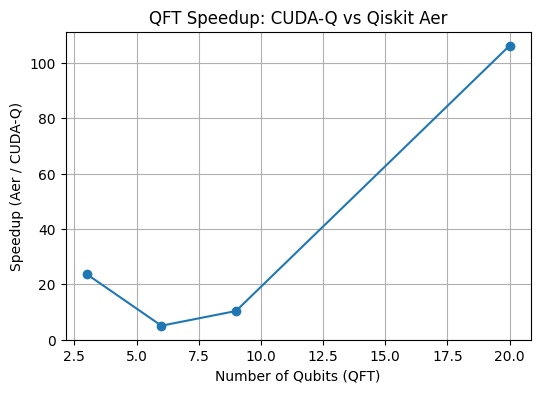
import osimport numpy as npfrom time import timefrom qiskit import QuantumCircuit, transpilefrom qiskit.circuit.library import QFTfrom qiskit_aer import AerSimulatorfrom qgear.toolbox.Util_CudaQ import qiskit_to_gateListfrom qgear.runner import run_cudaqfrom qgear.toolbox.Util_H5io4 import write4_data_hdf5, read4_data_hdf5from qiskit.quantum_info import Statevectorfrom qiskit_aer import StatevectorSimulatordef benchmark_qft(n_qubits=5, numShots=1000, backend_cudaq="nvidia", verb=0):""" Compare CUDA-Q vs Qiskit Aer for QFT circuit. """# ----------------------------# 1. Create QFT circuit qc = QFT(num_qubits=n_qubits, do_swaps=False).decompose() sv_qiskit = Statevector(qc) qc.measure_all() qcEL = [qc]# print("\n--- Qiskit Circuit ---")# print(qc.draw("text"))# ----------------------------# 2. CUDA-Q path out_path ="out" os.makedirs(out_path, exist_ok=True) circ_name =f"qft_{n_qubits}q" gateD, md = qiskit_to_gateList(qcEL)# dont save for now inpF = os.path.join(out_path, circ_name +".gate_list.h5") md["short_name"] = circ_name write4_data_hdf5(gateD, inpF, md) gateD, MD = read4_data_hdf5(inpF, verb) T0 = time() resL_cudaq,stateL = run_cudaq(gateD, numShots, verb=verb, backend=backend_cudaq) sv_cudaq = stateL[0] resL_cudaq = counts_cudaq_to_qiskit(resL_cudaq)# Fidelity check# print(resL_cudaq[0]) ela_cudaq = time() - T0# ----------------------------# 3. Qiskit Aer path aer_backend = AerSimulator() qcT = transpile(qc, aer_backend) T1 = time() job = aer_backend.run(qcT, shots=numShots) res_aer = job.result().get_counts() fidelity =abs(np.vdot(sv_qiskit, np.array(sv_cudaq)))**2print("Statevector fidelity:", fidelity)# print(res_aer) ela_aer = time() - T1# ----------------------------# 4. Reportprint(f"\n=== QFT {n_qubits} qubits ===")print(f"CUDA-Q ({backend_cudaq}): {ela_cudaq:.4f} s")print(f"AerSimulator: {ela_aer:.4f} s") speedup = ela_aer / ela_cudaq if ela_cudaq >0elsefloat('inf')print(f"Speedup (Aer / CUDA-Q): {speedup:.2f}x"if speedup >1elsef"CUDA-Q slower by {1/speedup:.2f}x")return ela_cudaq, ela_aer# ----------------------------# Run benchmarks for increasing QFT sizesresults = []for nq in [3, 6, 9, 20]: results.append((nq, *benchmark_qft(n_qubits=nq, numShots=2000, backend_cudaq="nvidia", verb=1)))# ----------------------------# Optional: Plot speedupimport matplotlib.pyplot as pltnq_list = [r[0] for r in results]cudaq_times = [r[1] for r in results]aer_times = [r[2] for r in results]speedups = [a/b for a, b inzip(aer_times, cudaq_times)]plt.figure(figsize=(6,4))plt.plot(nq_list, speedups, marker='o')plt.xlabel("Number of Qubits (QFT)")plt.ylabel("Speedup (Aer / CUDA-Q)")plt.title("QFT Speedup: CUDA-Q vs Qiskit Aer")plt.grid(True)plt.show()
/tmp/ipykernel_657/378558003.py:19: DeprecationWarning: The class ``qiskit.circuit.library.basis_change.qft.QFT`` is deprecated as of Qiskit 2.1. It will be removed in Qiskit 3.0. ('Use qiskit.circuit.library.QFTGate or qiskit.synthesis.qft.synth_qft_full instead, for access to all previous arguments.',)
qc = QFT(num_qubits=n_qubits, do_swaps=False).decompose()